"Astra DBは単なるツールではない。これは開発者が生成AIの可能性を最大限に活用するための強いフォースとなります。"
各業界に影響を与える生成AIのリーダーたち











ワンストップ生成AIスタック
すべてのデータ、ツール、そして機能する制約があるが生産性の高いスタックを備えたRAG API。ベクトルデータも構造化データも、安全で、コンプライアンスに準拠し、スケーラブルで、サポートされています。LangChain、Vercel、GitHub Copilot、AIエコシステムをリードするソフトウェアと統合されています。
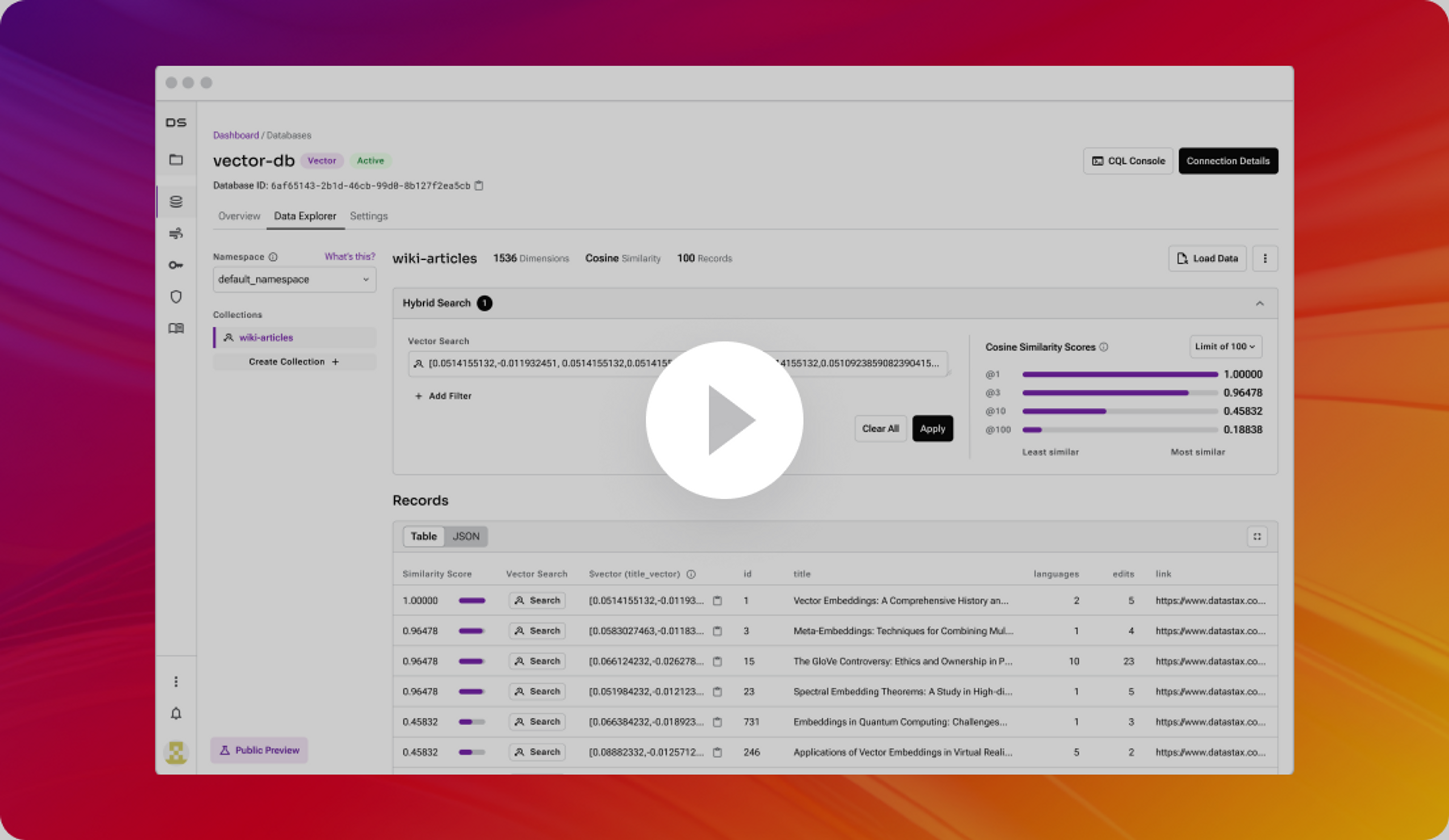
利用者に適合する生成AI
Pineconeと比較して、TCOを80%削減しながら、利用者の要求への適合性を20%高め、74倍のレスポンスタイムと9倍のスループットを実現し、インデックス作成中に読み出しを行い、ゼロ遅延でデータを更新することができます。
プロダクション環境を迅速に
生成AIのアイデアを迅速にプロダクション環境に導きます。プロダクション環境のAIワークロードをリードしてエンタープライズレベルのセキュリティとコンプライアンスとともに展開し、あらゆるクラウド上でグローバルなスケールを実現します。

生成AIの素晴らしい開発者体験
生成AIは楽しくあるべきです。LangChain、GitHub、VercelなどのAIエコシステムのリーディングパートナーが、JavaScript、Python、Java、C++の開発者に素晴らしい体験をもたらし、生成AIアプリをプロダクション環境で稼働させることができます。
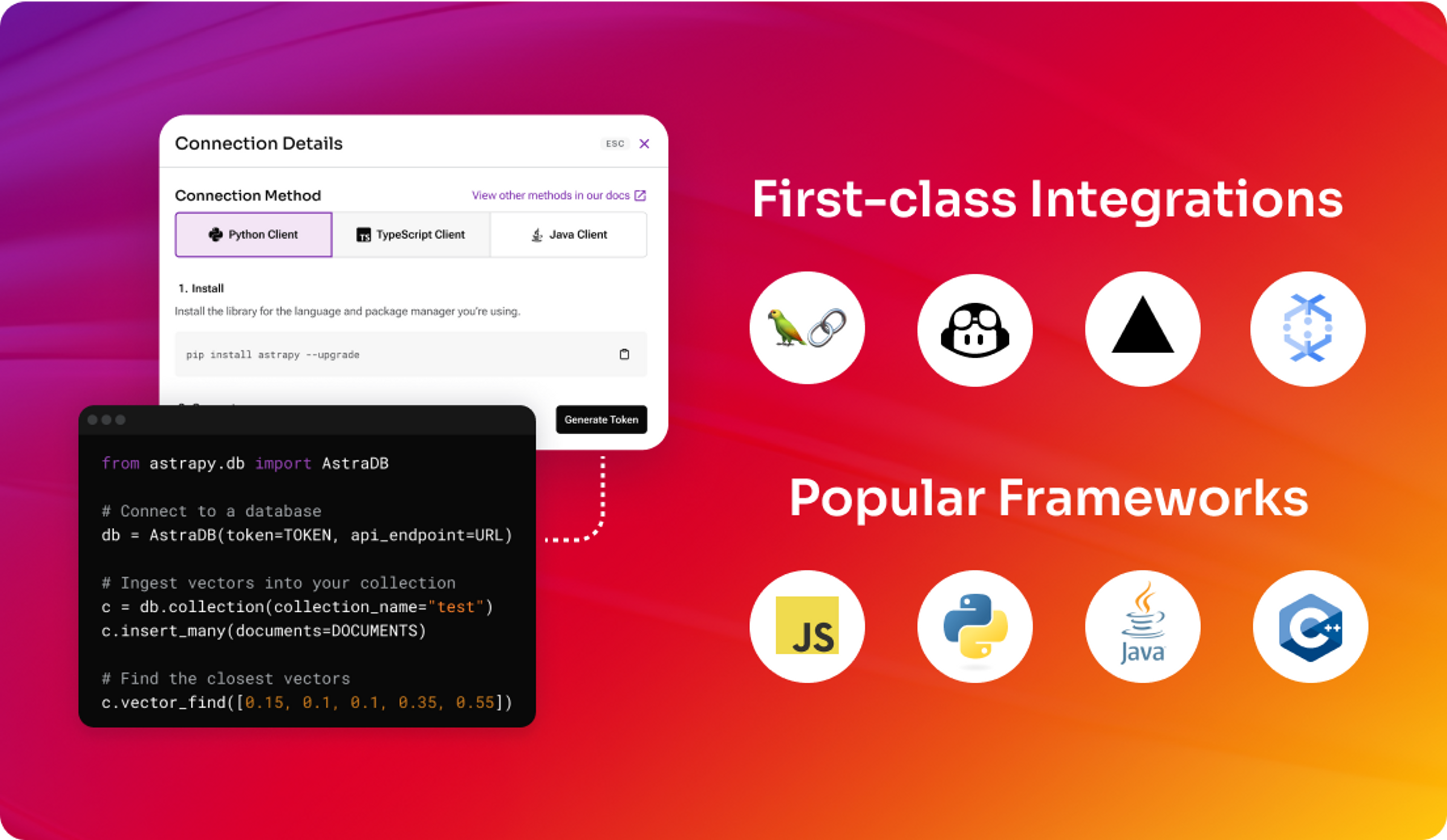
開発者の方へ
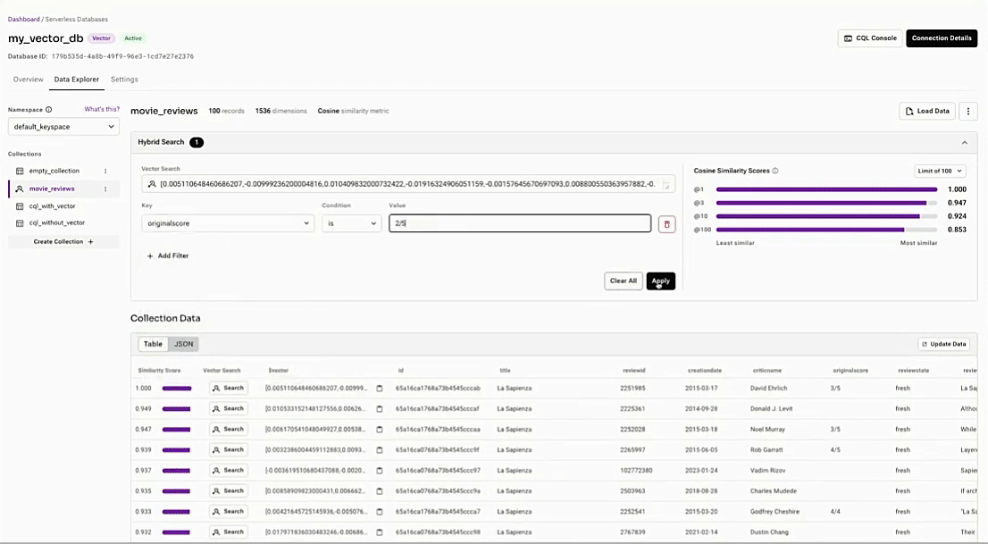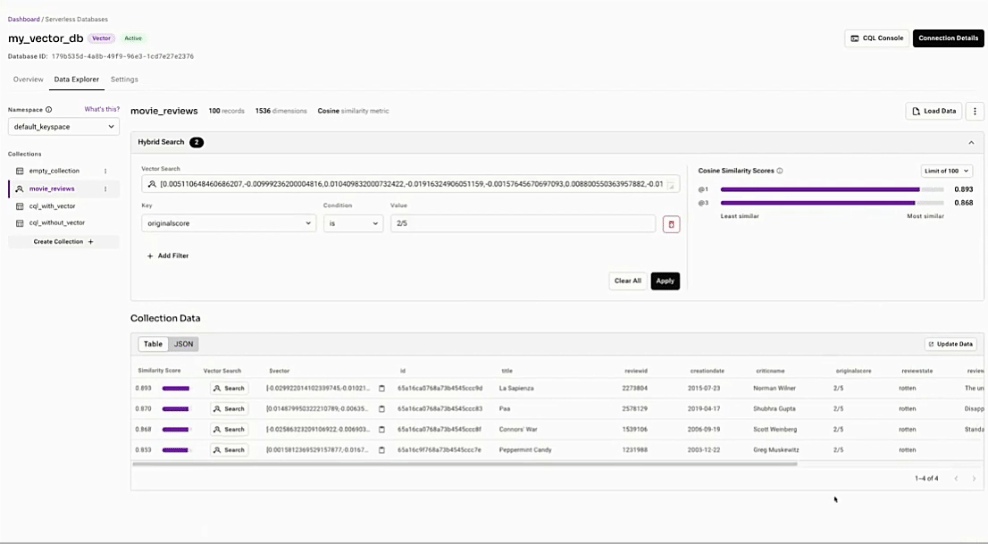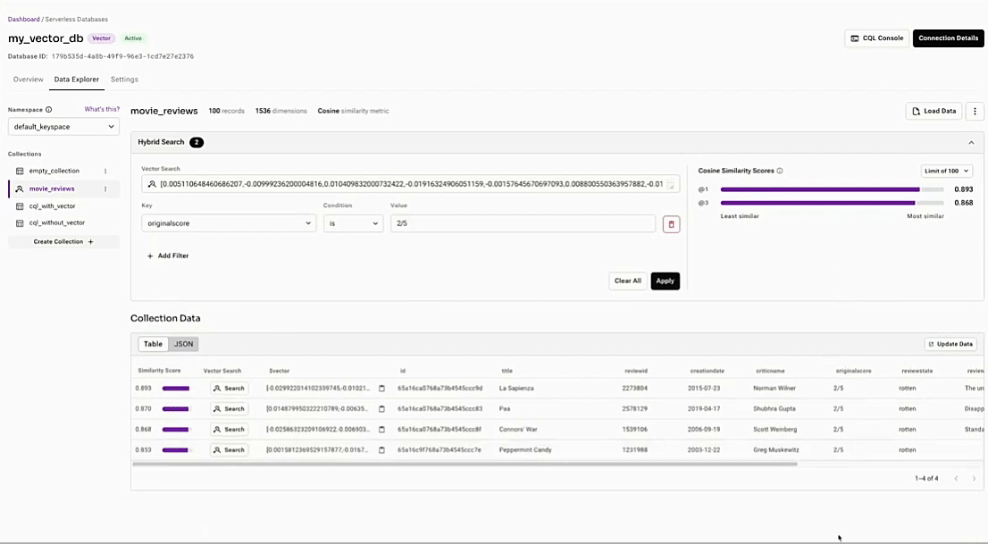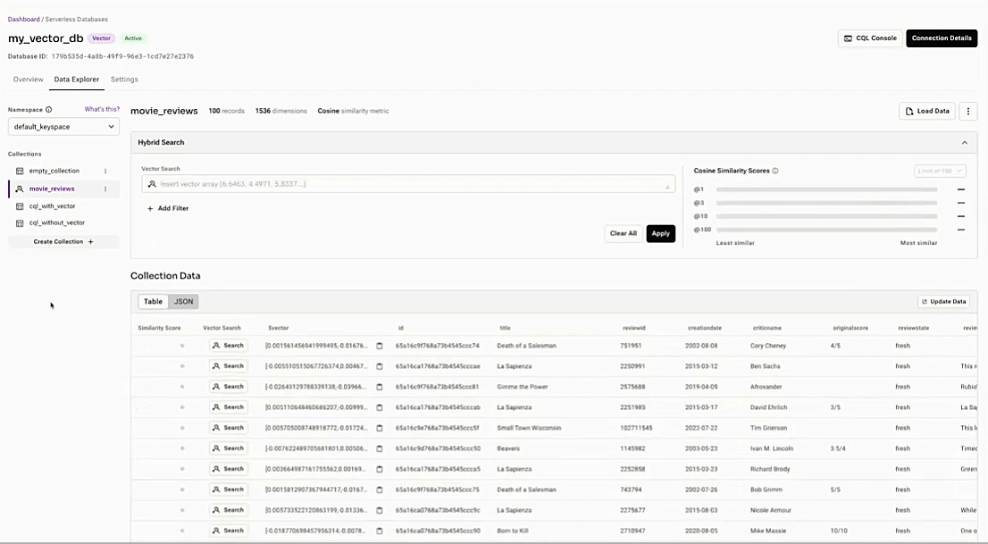
RAGを簡単に
使いやすいAPIと、プロダクション・レベルのRAGとFLAREのためのパワフルな統合。
Install
Astra libraryをインストール
pythonjavascriptjava
pip install astrapy
npm install @datastax/astra-db-ts
Maven:<dependency>
<groupid>com.datastax.astra</groupid>
<artifactid>astra-db-client</artifactid>
<version>1.2.4</version>
</dependency>
Gradle:
dependencies {
implementation 'com.datastax.astra:astra-db-client:1.2.4'
}Create
コレクションを作成、または、既にあるコレクションに接続
pythonjavascriptjava
# The return of create_collection() will return the collection collection = astra_db.create_collection( collection_name="collection_test", dimension=5 ) # Or you can connect to an existing connection directly collection = AstraDBCollection( collection_name="collection_test", astra_db=astra_db ) # You don't even need the astra_db object collection = AstraDBCollection( collection_name="collection_test", token=token, api_endpoint=api_endpoint )
/ Create a vector collection const collection = await db.createCollection("collection_test", { vector: { dimension: 5, metric: "cosine", }, }); // Or you can connect to an existing collection const collection = await db.collection('collection_test');AstraDB db = new AstraDB("token", "endpoint"); AstraDBCollection collection = db.createCollection("vector_test", 5);Insert
既にあるベクトルストア(コレクション)にベクトルオブジェクトを挿入
pythonjavascriptjava
collection.insert_one( { "_id": "5", "name": "Coded Cleats Copy", "description": "ChatGPT integrated sneakers that talk to you", "$vector": [0.25, 0.25, 0.25, 0.25, 0.25], } )const doc = await collection.insertOne({ "_id": "5", "$vector": [0.25, 0.25, 0.25, 0.25, 0.25], "name": "Coded Cleats Copy", "description": "ChatGPT integrated sneakers that talk to you", });collection.insertOne(new JsonDocument() .put("text", "ChatGPT integrated sneakers that talk to you") .vector(new float[]{0.1f, 0.15f, 0.3f, 0.12f, 0.05f}));Find
ベクトル検索を使ってドキュメントを見つける
pythonjavascriptjava
documents = collection.vector_find( [0.15, 0.1, 0.1, 0.35, 0.55], limit=100, )
const results = await collection.find(null, { sort: { $vector: [0.15, 0.1, 0.1, 0.35, 0.55], }, limit: 100, }) .toArray();float[] embeddings = new float[] {0.1f, 0.15f, 0.3f, 0.12f, 0.05f};
Filter metadataFilter = new Filter().where("text", EQUALS_TO, "ChatGPT");
Stream<jsondocumentresult>rag =
collection.findVector(embeddings, metadataFilter, 10);</jsondocumentresult>